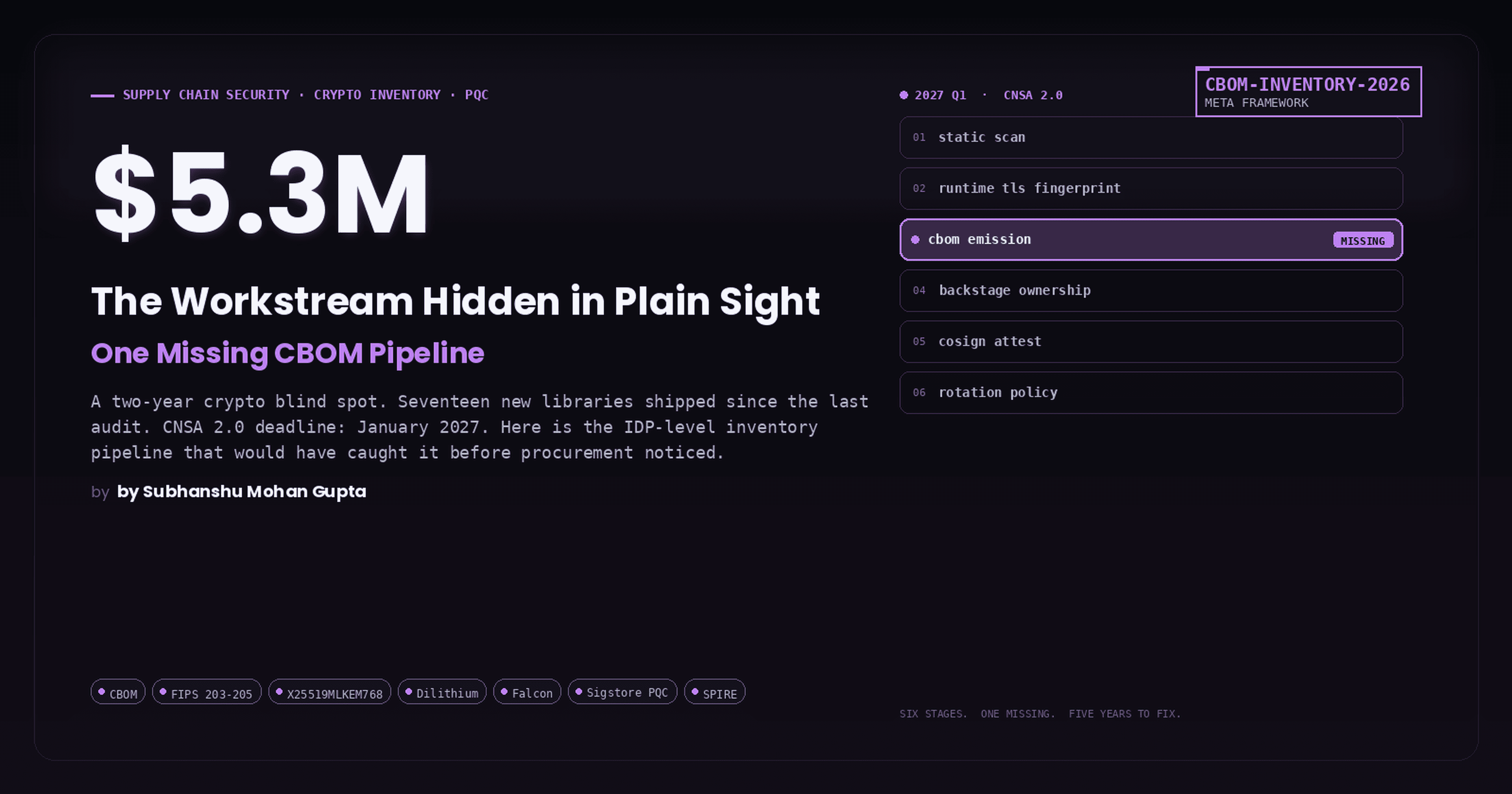
The Global Cloud Blackout
Designing Systems That Survive Regional Collapse, Provider Failure & Digital Fragmentation

A versatile DevSecOps Engineer specialized in creating secure, scalable, and efficient systems that bridge development and operations. My expertise lies in automating complex processes, integrating AI-driven solutions, and ensuring seamless, secure delivery pipelines. With a deep understanding of cloud infrastructure, CI/CD, and cybersecurity, I thrive on solving challenges at the intersection of innovation and security, driving continuous improvement in both technology and team dynamics.
If AWS disappeared tomorrow, would your company survive?
Not degraded. Not slow. Gone.
Most "highly available" systems would collapse within hours. This isn't fear-mongering. It's an architectural reality that 90% of engineering teams refuse to confront.
This article is not a theory piece. It's a survival blueprint with real architecture, real code, and a real-world case study you can follow end to end.
The Real-World Wake-Up Call
December 7, 2021: The Day us-east-1 Broke the Internet
At 7:35 AM PST, AWS us-east-1 experienced a cascading failure. Here's what actually happened and why it matters:
The Trigger: A networking issue disrupted communication between internal AWS services in us-east-1. This wasn't a power outage. It wasn't a natural disaster. It was an internal control plane failure.
The Cascade:
AWS Console became unreachable and teams couldn't even see their infrastructure
DynamoDB, Lambda, SQS, Kinesis were all degraded or unavailable
CloudWatch stopped reporting, so teams were flying blind
Even the AWS Status Page was down because it was hosted on... AWS
The Real-World Damage:
Disney+, Netflix, Slack, Venmo, Coinbase all experienced outages
Robinhood users couldn't execute trades during market hours
Warehouse robots at Amazon's own fulfillment centers stopped working
Ring doorbell cameras went dark across millions of homes
Thousands of companies with "99.99% availability" architectures went completely offline
The Uncomfortable Truth:
Every one of these companies had multi-AZ deployments. Many had auto-scaling. Some even had multi-region configurations. But almost none had control-plane independence.
When AWS couldn't talk to itself, it didn't matter how many availability zones you had.

Lesson: Multi-AZ is not resilience. Multi-region is not sovereignty. Multi-cloud without control-plane independence is illusion.
This incident, along with the Azure global authentication failure of March 2021 and the Cloudflare DNS disruption of June 2022, led me to develop what I call:
Survival-Grade Cloud Architecture (SGCA)
A framework for designing systems that don't just survive component failures; they survive provider failures.
The 4 Blackout Threat Models
Before we architect solutions, we need to understand what we're designing against. Not theoretical scenarios, but real failure modes that have already happened.
Threat Model 1: Regional Infrastructure Collapse
What: An entire cloud region goes dark. Power grid failure, network backbone cut, physical disaster.
Real precedent: The 2012 AWS us-east-1 outage caused by severe storms in Virginia knocked out power to multiple data centers simultaneously. Backup generators failed at some facilities.
Why Multi-AZ fails here: All availability zones within a region share the same regional backbone, power grid dependencies, and often the same physical geography.

Threat Model 2: Control Plane Failure
What: The cloud's management APIs, IAM, provisioning systems become unreachable. Your workloads might still run, but you cannot manage, scale, deploy, or authenticate.
Real precedent: The December 2021 us-east-1 outage was fundamentally a control-plane failure. Also, Azure AD's global authentication outage in March 2021 locked users out of Microsoft 365, Azure Portal, and every application using Azure AD for SSO, worldwide.
Why this is devastating: If you use AWS IAM for authentication, AWS Secrets Manager for credentials, and AWS CloudWatch for monitoring, a control plane failure means you're deaf, mute, and blind simultaneously.
Threat Model 3: DNS / Routing-Level Disruption
What: DNS resolution fails or is hijacked. BGP routes are corrupted. Traffic literally cannot find your services.
Real precedent: In June 2022, Cloudflare experienced an outage affecting 19 data centers due to a BGP routing change gone wrong. In October 2021, Facebook/Meta disappeared from the internet entirely for ~6 hours because of a BGP withdrawal that also took down their internal DNS.
Impact: It doesn't matter if your servers are running perfectly. If DNS can't resolve your domain, you don't exist on the internet.
Threat Model 4: Geopolitical / Sovereign Isolation
What: Government sanctions block access to a cloud provider. Data sovereignty laws force isolation. A country-level firewall blocks traffic.
Real precedent: When sanctions were imposed on Russian entities in 2022, AWS and Azure suspended accounts, leaving affected businesses with zero access to their infrastructure. China's Great Firewall regularly disrupts traffic to foreign cloud services.
Impact: Your entire infrastructure becomes legally or physically inaccessible. Not because it failed, but because access was revoked.
⚠️ Pause and ask yourself: If your cloud console is unreachable right now, can you still deploy? Can users still log in? Can you even see what's happening?
If the answer is no to any of these, keep reading.
Survival-Grade Architecture Blueprint
Here's the complete 4-layer architecture that survives all four threat models:

Let's break down each layer.
Layer 1: Independent Global Traffic Authority
The Golden Rule: DNS must not depend on the cloud it routes to.
If you're using Route53 to route traffic to AWS, and AWS goes down, your DNS goes down with it. This is the most common single point of failure in "multi-cloud" architectures.
Design Principles:
Dual DNS providers: Cloudflare as primary, NS1 (or Google Cloud DNS) as secondary
Health-based routing: Active health checks against each cloud's endpoints, not just TCP ping but actual application-level health (
/healthzreturning 200 + data freshness check)Aggressive TTL: 30-second TTL for DNS records so failover propagates in under a minute
Anycast: Use a DNS provider with anycast networking so DNS resolution itself is globally distributed and resilient

Layer 2: Active-Active Multi-Cloud Compute
This is where Kubernetes becomes your portability layer. The key insight: your container is your contract. If the same container runs on EKS and GKE, your application is cloud-agnostic.
Architecture:
AWS EKS cluster as primary compute
GCP GKE cluster as secondary compute (always warm, always running)
ArgoCD installed in both clusters, both pulling from the same Git repository
Identical container images pushed to both ECR and GCR via CI pipeline
Traffic shift = DNS routing change, not a deployment event

Key Rule: The control plane of your compute must not depend on a single cloud. ArgoCD gives you this. It's your control plane, not AWS's.
Layer 3: Data Survival Strategy (The Hardest Layer)
Data is where multi-cloud gets genuinely hard. You have three models, each with real trade-offs:
Model A: Globally Distributed SQL (CockroachDB / YugabyteDB)
True active-active writes across clouds
Automatic conflict resolution via consensus protocol
RPO: Near-zero (seconds)
Trade-off: Higher write latency (~50-100ms cross-region), higher cost, operational complexity
Model B: Event-Sourced Architecture (Kafka Multi-Cluster)
All state changes captured as immutable events
Kafka MirrorMaker 2 replicates across clusters
State can be reconstructed from event replay
RPO: Seconds to minutes depending on replication lag
Trade-off: Application must be designed for event sourcing from the start
Model C: Async Cross-Cloud Replication
Primary database (e.g., RDS PostgreSQL) with async replication to secondary cloud
Object storage sync (S3 → GCS)
RPO: Minutes (replication lag)
Trade-off: Data loss window during failover, conflict resolution needed
Comparison:
| Factor | Model A (CockroachDB) | Model B (Event-Sourced) | Model C (Async Replication) |
|---|---|---|---|
| RPO | ~0 seconds | 1-30 seconds | 1-5 minutes |
| Write Latency | 50-100ms | 5-15ms local | 5-10ms local |
| Complexity | High | Very High | Medium |
| Monthly Cost (est.) | $3,000-8,000 | $2,000-5,000 | $500-1,500 |
| Best For | Financial, healthcare | Event-driven platforms | Cost-sensitive, read-heavy |
| Retrofit Difficulty | Medium | Very Hard | Easy |
My Recommendation: For most teams, start with Model C for your database and Model B for your event bus. Graduate to Model A when your business criticality demands near-zero RPO.
Layer 4: Identity Independence
If AWS IAM goes down, can your users still log in? If your secrets are only in AWS Secrets Manager, can your GCP services authenticate?
Design:
Self-hosted IdP: Keycloak deployed on both clouds, backed by the replicated database
Federated OIDC tokens: Applications validate JWT tokens, not cloud-specific IAM policies
HashiCorp Vault: Secrets replicated across both clouds, auto-unsealed independently
mTLS via service mesh: Istio/Linkerd for inter-service auth that doesn't depend on any cloud IAM

Never bind authentication exclusively to one hyperscaler. This is the #1 mistake I see in "multi-cloud" architectures.
Real-World Example
Building a Blackout-Proof E-Commerce Platform: "ShopGlobal"
Let me walk you through a real scenario. ShopGlobal is a mid-size e-commerce company processing $2M/day in orders. They run entirely on AWS. Here's what happened and how they rebuilt.
The Incident
On a Tuesday morning, AWS us-east-1 experienced a partial control-plane outage. ShopGlobal's impact:
Payment service went down. Secrets Manager unreachable, Stripe API keys inaccessible.
Auth went down. Cognito unavailable. No user could log in.
Product catalog degraded. DynamoDB throttled, eventually unreachable.
Order processing went down. SQS backed up, Lambda couldn't provision.
Monitoring went down. CloudWatch unreachable. Team couldn't see what was failing.
Total downtime: 4 hours 22 minutes Revenue lost: ~$370,000 Customer trust impact: 12% increase in churn that quarter
The Rebuild: Applying SGCA
Here's how ShopGlobal rebuilt using the Survival-Grade Architecture:

Results after rebuild:
Next us-east-1 degradation → Automatic failover in 47 seconds
Zero revenue lost
Users didn't notice
Cloud Exit Time: < 2 minutes
Step-by-Step Implementation Guide
The entire working implementation is open-sourced. Clone the repo and follow along:
🔗 GitHub Repository: github.com/SubhanshuMG/survival-grade-infra
survival-grade-infra/
├── terraform/
│ ├── main.tf # Multi-cloud providers + Cloudflare DNS failover
│ ├── variables.tf # All configurable parameters
│ ├── outputs.tf
│ ├── modules/
│ │ ├── eks/ # AWS EKS cluster module
│ │ │ ├── main.tf
│ │ │ ├── variables.tf
│ │ │ └── outputs.tf
│ │ ├── gke/ # GCP GKE cluster module
│ │ │ ├── main.tf
│ │ │ ├── variables.tf
│ │ │ └── outputs.tf
│ │ └── dns/
│ │ ├── main.tf
│ │ └── variables.tf
├── k8s/
│ ├── base/ # Shared Kubernetes manifests
│ │ ├── namespace.yaml
│ │ ├── deployment.yaml
│ │ ├── service.yaml
│ │ └── ingress.yaml
│ ├── overlays/ # Cloud-specific Kustomize patches
│ │ ├── aws/
│ │ │ └── kustomization.yaml
│ │ └── gcp/
│ │ └── kustomization.yaml
│ ├── argocd/ # GitOps Application definitions
│ │ ├── app-aws.yaml
│ │ └── app-gcp.yaml
│ └── base/
│ ├── cockroachdb-multicloud.yaml # CockroachDB StatefulSet
│ └── keycloak.yaml # Identity layer
├── src/
│ └── storage-sync/
│ └── sync-worker.py # Cross-cloud S3→GCS replication
├── ci/
│ └── .github/workflows/
│ └── multi-cloud-deploy.yaml # Build + sign + push to ECR & GCR
├── chaos/
│ ├── blackout-test.sh # Full blackout drill script
│ └── dns-failover-test.sh
└── docker/
└── Dockerfile
Let's walk through what each piece does and why it exists.
Step 1: Terraform Multi-Cloud Infrastructure
All configurable parameters: project name, AWS/GCP regions, Cloudflare zone, node counts, and instance types. Change these values once and every module inherits them.
This is the core of the entire infrastructure. Here's what it provisions and why:
AWS VPC + EKS cluster with nodes spread across 3 availability zones, NAT gateways per AZ (not a single shared one), and proper subnet tagging for Kubernetes load balancers
GCP GKE cluster with workload identity enabled, node autoscaling, and a separately managed node pool (never use the default pool in production)
Cloudflare health checks hitting
/healthzon both clouds every 30 seconds. These aren't TCP pings. They're full HTTPS requests that verify the application is actually serving traffic.Cloudflare Load Balancer with geo-based steering: US East traffic goes to AWS, US Central goes to GCP. If either cloud fails the health check, all traffic shifts to the surviving cloud within one TTL cycle (30 seconds).
The critical design decision here: DNS and traffic routing live on Cloudflare, completely independent of both AWS and GCP. If either cloud burns down, the routing layer keeps working.
📁 terraform/modules/eks/main.tf
EKS module using the official terraform-aws-modules/eks/aws with IRSA enabled for pod-level IAM. Nodes are in a managed node group with autoscaling set to 2x the baseline.
📁 terraform/modules/gke/main.tf
GKE module with VPC-native networking, workload identity, and the REGULAR release channel. The default node pool is removed immediately and replaced with a custom one (this is a GKE best practice that most teams skip).
Step 2: Kubernetes Application Manifests
The manifests use Kustomize with a base + overlays pattern. One set of base manifests, two cloud-specific overlays.
The deployment includes topology spread constraints to distribute pods evenly across zones, readiness and liveness probes on /healthz, and environment variables pulled from ConfigMaps and Secrets. The image tag is a placeholder that each overlay replaces with the correct cloud-specific registry URL.
ClusterIP service + Ingress with TLS via cert-manager. Both clouds serve the same hostname app.shopglobal.com because Cloudflare handles which cloud actually receives the traffic.
📁 k8s/overlays/aws/kustomization.yaml 📁 k8s/overlays/gcp/kustomization.yaml
Each overlay patches three things: the container image registry (ECR vs GCR), the Kafka broker addresses (AWS cluster vs GCP cluster), and the auth issuer URL. Everything else stays identical. Same application code, same configuration structure, different cloud-specific endpoints.
Step 3: ArgoCD Multi-Cluster GitOps
📁 k8s/argocd/app-aws.yaml 📁 k8s/argocd/app-gcp.yaml
ArgoCD is installed independently on both clusters. Each instance pulls from the same Git repo but points to its respective Kustomize overlay. Auto-sync is enabled with self-healing and pruning turned on.
This is the key insight of the entire compute layer: you never deploy to two clouds. You push to Git once. Both ArgoCD instances independently sync the change. If you need to fail over, you change a DNS weight, not a deployment pipeline. There's nothing to "redeploy" because both clouds are always running the latest version.
Slack notifications are configured on sync failures so your on-call team knows immediately if a cloud falls out of sync.
Step 4: CI/CD Multi-Cloud Image Pipeline
📁 ci/.github/workflows/multi-cloud-deploy.yaml
The pipeline does five things on every push to main:
Builds the container image once using Docker Buildx
Tags and pushes to AWS ECR using OIDC-based authentication (no long-lived AWS keys in GitHub)
Tags and pushes to GCP Artifact Registry using workload identity federation (same principle, no keys)
Signs both images with Cosign so both clusters can verify the image hasn't been tampered with
Updates the Kustomize overlays with the new image tag and commits back to the repo, which triggers ArgoCD sync on both clouds
The image tag format is <short-sha>-<unix-timestamp> to guarantee uniqueness and traceability. Both registries always have identical images. If one registry becomes unreachable, the other cloud still has its copy.
Step 5: CockroachDB Multi-Cloud Deployment
📁 k8s/base/cockroachdb-multicloud.yaml
CockroachDB runs as a StatefulSet with 3 nodes per cloud (6 total). The replication zone is configured with locality-aware constraints: at least 2 replicas on AWS, at least 2 on GCP. The database is set to SURVIVE REGION FAILURE, meaning it maintains consensus even if an entire cloud goes offline.
Each node advertises its locality as cloud=aws,region=us-east-1 or cloud=gcp,region=us-central1. CockroachDB uses this to make intelligent placement decisions, keeping reads local while ensuring writes are replicated cross-cloud before acknowledging.
The persistent volumes use 100Gi with ReadWriteOnce access. In production, you'll want to tune --cache and --max-sql-memory based on your node size.
Step 6: Cross-Cloud Object Storage Sync
📁 src/storage-sync/sync-worker.py
This is an event-driven replication worker, not a cron job. It listens for S3 event notifications (via SQS or EventBridge) and replicates each object to GCS in real-time with MD5 integrity verification. On startup, it runs a full bucket reconciliation to catch anything that was missed.
Deletions are mirrored too. If an object is removed from S3, the worker removes it from GCS. The full reconciliation compares object sizes and only re-syncs what's actually different, so it's safe to run repeatedly without hammering your bandwidth.
Deploy this as a Kubernetes Deployment on both clouds. The AWS instance handles S3→GCS direction. A mirrored instance on GCP handles GCS→S3. Bidirectional sync with conflict resolution by last-write-wins.
Step 7: Keycloak Multi-Cloud Identity Setup
Keycloak runs as a 2-replica Deployment backed by CockroachDB (the same database that's already replicated across clouds). This means Keycloak on GCP automatically has the same user database, sessions, and realm configurations as Keycloak on AWS. No separate identity sync needed.
Cluster discovery between Keycloak instances uses a headless Kubernetes service with JGroups DNS_PING. The Infinispan cache is set to kubernetes stack mode so session data is shared across replicas within each cloud.
Both Keycloak instances serve auth.shopglobal.com, and Cloudflare routes auth traffic the same way it routes application traffic. If AWS goes down, users authenticate against GCP's Keycloak, which has the exact same data because it reads from the same CockroachDB cluster.
This is why CockroachDB was chosen over simpler database options. It's not just for application data; it's the shared backbone that makes identity, sessions, and secrets work cross-cloud without custom sync pipelines.
Chaos Blackout Testing Strategy
Architecture without testing is fiction. Here's how you prove it works.
Blackout Drill Script
This is a 6-phase automated drill that simulates a complete primary cloud failure and grades your architecture. Run it quarterly. Make it policy, not optional.
Phase 1: Baseline Measurement Records current latency, writes test data to the primary cloud, and verifies both endpoints are healthy before the drill begins. If either cloud is already unhealthy, the script aborts.
Phase 2: Simulate Primary Cloud Failure Disables the AWS pool in Cloudflare's load balancer via API. This is identical to what happens during a real outage from the DNS perspective. Traffic has nowhere to go on the primary side.
Phase 3: Measure Failover Polls the application endpoint every second, counting how long until a 200 response comes back (now served from GCP). This is your actual, measured RTO. Not a theoretical number from a spreadsheet. The real thing.
Phase 4: Data Integrity Check Reads back the test data that was written before the failover. If it's accessible on the secondary cloud, your data replication is working. Then writes new data on the secondary and reads it back to confirm write continuity.
Phase 5: Verify Auth Flow Hits the Keycloak OIDC discovery endpoint to confirm authentication is working on the surviving cloud. If users can't log in, surviving the outage doesn't matter.
Phase 6: Restore Primary Re-enables the AWS pool, waits for health checks to pass, and confirms the primary cloud is back in the rotation.
The script outputs a final report card and sends results to Slack:
═══════════════════════════════════════════
BLACKOUT DRILL RESULTS
═══════════════════════════════════════════
RTO (Recovery Time): 42.37s
RPO (Data Integrity): PASS
Auth Continuity: PASS
Post-Restore Health: PASS
GRADE: A. Survival-grade resilience confirmed
Grading criteria:
Grade A: RTO under 60 seconds + RPO pass
Grade B: RTO under 300 seconds
Grade F: Everything else
What This Tests
| Test Area | How It's Validated |
|---|---|
| DNS Failover | Cloudflare pool disable via API |
| Compute Failover | All traffic shifts to GCP automatically |
| Data Integrity | Pre-failover data read from secondary |
| Write Continuity | Post-failover write + read on secondary |
| Auth Continuity | Keycloak OIDC discovery endpoint check |
| Recovery | Primary re-enable + health verification |
Run quarterly. No exceptions. "Reliability without testing is fiction."
Resilience Maturity Model
Use this to assess where you are and where you need to be:
| Tier | Architecture | What It Survives | What Kills It | Typical Org |
|---|---|---|---|---|
| Tier 0 | Multi-AZ | Single AZ failure | Region outage, control plane failure | Startups, MVPs |
| Tier 1 | Multi-Region | Region failure | Provider-wide outage, DNS failure | Growing SaaS |
| Tier 2 | Multi-Cloud Passive | Provider outage (with manual failover) | Slow RTO, data loss during cutover | Enterprise |
| Tier 3 | Multi-Cloud Active-Active | Provider outage (automatic) | Geopolitical isolation, regulatory block | Mission-Critical |
| Tier 4 | Sovereign Split | Everything above + data sovereignty | Nation-state level infrastructure attack | Global Enterprise, Defense |
New Metrics: Your Resilience Scorecard
I'm introducing three metrics that I believe every organization should track:
Cloud Exit Time (CET) How long to fully operate from an alternate provider after your primary disappears.
Tier 0-1 organizations: CET is typically "unknown" or "weeks"
Tier 3-4 organizations: CET should be under 2 minutes
Control Plane Dependency Index (CPDI) What percentage of your infrastructure depends on a single provider's APIs?
Count every service: IAM, DNS, secrets, monitoring, logging, CI/CD, container registry
If CPDI > 70%, you have a single-cloud architecture wearing a multi-cloud costume
Data Replication Confidence Score (DRCS) Measured empirically via quarterly blackout drills, not theoretical.
DRCS = (Successful data reads post-failover / Total data written pre-failover) × 100
If you haven't tested it, your DRCS is 0%. Not "assumed 99%." Zero.
The Strategic Close
Cloud resilience is no longer a technical problem. It's a geopolitical and architectural problem.
The companies that will survive the next decade aren't the ones with the most availability zones. They're the ones with provider independence, data sovereignty, and the discipline to test their survival assumptions quarterly.
Here's what you should do this week:
Calculate your CPDI. List every cloud-specific service you depend on. Be honest.
Define your CET. If your primary cloud disappeared right now, how long until you're operational elsewhere? If you don't know, the answer is "too long."
Schedule your first blackout drill. Even if it's just a tabletop exercise. Start somewhere.
Move DNS off your primary cloud. This is the single highest-impact, lowest-effort change you can make today.
The architecture in this article isn't theoretical. It's what separates companies that survive outages from companies that make headlines during them.
If your cloud provider disappeared tomorrow, would your system survive?
If not, you now have the blueprint to fix it.